NVIDIA and Red Hat Just Closed the Enterprise AI Production Gap
NVIDIA and Red Hat Just Closed the Enterprise AI Production Gap
Most enterprises have AI in production. Almost none of it touches their most valuable data. The gap between "AI at the edge of sensitive information" and "AI inside it" has always been a trust problem. This month, NVIDIA and Red Hat turned it into an infrastructure problem. Infrastructure problems have solutions.
WHAT SHIPPED
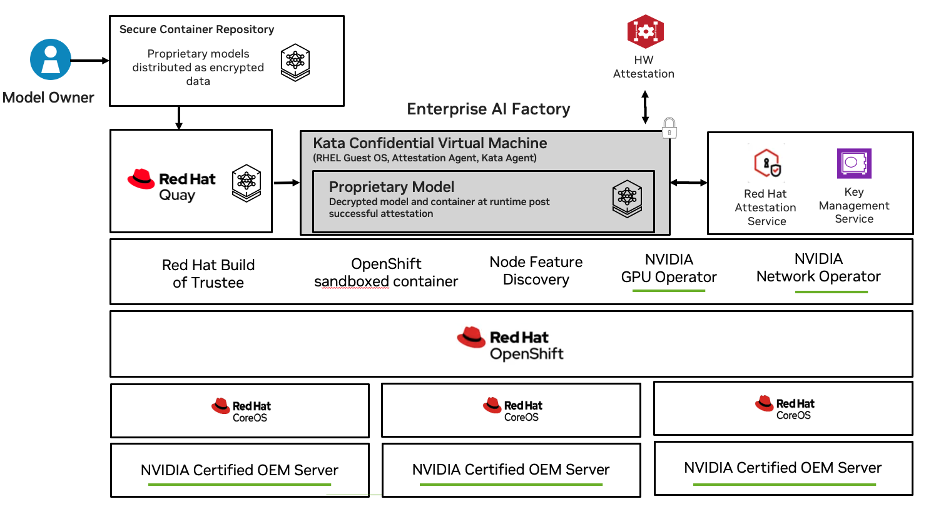
NVIDIA's Confidential Containers (CoCo) is generally available this month. Red Hat is shipping CoCo on OpenShift on the same timeline. The scope matters: Intel TDX, AMD SEV-SNP, NVIDIA Hopper, HGX, Blackwell HGX, RTX PRO™ — single and multi-GPU passthrough, all Kubernetes-native, with lift-and-shift capability for workloads you've already built.
That last part is worth slowing down on. Lift-and-shift means your existing GPU workloads, running in your existing Kubernetes environments, can now run inside hardware-backed Trusted Execution Environments (TEEs) without a rewrite. NVIDIA shipped this as a Kubernetes operator. Red Hat integrated it into OpenShift. The deployment story is: install the operator, update the pod spec, your workload runs in a TEE.
The architecture underneath is Kata Containers with NVIDIA GPU passthrough via QEMU — a virtualization-based isolation layer that extends the TEE boundary into the GPU execution context. Zvonko Kaiser, NVIDIA's lead architect for Kata and Confidential Containers, has been driving this upstream. This isn't a proprietary NVIDIA stack bolted onto Kubernetes. It's built into the open standards the ecosystem is converging on.
Red Hat's GPU support ships as tech preview at GA. For most enterprise teams running OpenShift, that's still the fastest path to a credible production deployment of confidential GPU workloads — on infrastructure they already own and know how to operate.
THE PROBLEM THIS SOLVES
There's a category of AI use case that's been stuck — not in ideation, not in experimentation, but stuck after proof-of-concept. The model works. The business case is clear. And then someone in legal, compliance, or the data team asks a question that doesn't have a good answer yet: "What guarantees can you give us about what happens to our data inside the GPU?"
Consider what happens when an AI vendor sells a document intelligence product to a regulated enterprise — a bank, an insurer, a law firm. The vendor's model weights are their core IP: years of training, a proprietary architecture, the thing that makes the product work. The enterprise's input documents are regulated data: loan applications, medical records, M&A term sheets, client communications covered by confidentiality agreements. Both flow through the same GPU execution environment. And until now, neither party could give the other a technical guarantee about what happens inside it. The vendor's legal team writes a data processing agreement. The enterprise's legal team reviews it. Both sign. And somewhere on shared cloud infrastructure, a memory dump could expose the vendor's model weights and the enterprise's confidential documents simultaneously — with no cryptographic evidence of what happened, and no way to prove it didn't.
The same conversation plays out differently depending on who's in the room. For the enterprise CTO, it's the compliance team asking for cryptographic proof before they'll approve the production workload. For the AI vendor's engineering team, it's the customer's security review that kills the deal because the data processing agreement isn't a technical control. For the VP of Engineering on either side, it's the data governance policy that makes the answer "we have a contract" feel increasingly inadequate as the data gets more sensitive.
There's a second version of this problem that doesn't get enough attention: the model itself is the sensitive asset. When an organization fine-tunes a foundation model on proprietary data — patient records, clinical trial results, sovereign health datasets — the resulting model weights are a compressed representation of that data. They encode it. A memory dump of the GPU during inference doesn't just expose the inputs being processed. It exposes the model, which carries the training data inside it. For teams working with health data under GDPR or data sovereignty requirements, that's a regulatory exposure baked into the model artifact itself, not just into what you send it.
We're seeing this directly with partners like ATRC (Technology Innovation Institute, UAE), building sovereign AI capabilities by fine-tuning open-weight models like Falcon on highly sensitive national health data. The model that results is both IP and, in a meaningful sense, a vessel for the data it was trained on. Running it on infrastructure you can't cryptographically verify isn't just a security posture question. It's a data residency question, a sovereignty question, and increasingly a regulatory one.
The same pressure applies at the frontier. Frontier model labs are acutely focused on ensuring their model weights don't end up in the hands of actors who could weaponize them. Protecting model weights from extraction and misuse isn't an academic concern. It's an active one.
This is one instance of a structural problem. We mapped twelve of them in our research paper, A Dozen Ways Your AI Stack is Bleeding Data — validated across conversations with teams at Anthropic, ServiceNow, Accenture, NVIDIA, Intel, AMD, and Microsoft Azure. The bleeds span four trust boundaries: the compute plane, the control plane, the application layer, and the trust boundary itself. A memory dump exposes live inference. APM telemetry captures prompts and retains them for ninety days with a third party. An SDK phones home with enterprise queries by default. None of these look broken. The logs are clean. The system just bleeds.
Confidential Containers addresses the compute plane bleeds directly and changes the threat model for the others. Running inside a hardware-backed TEE, the workload is cryptographically isolated — from external attackers, from the orchestration layer, from the cloud provider's own infrastructure. Memory is encrypted. Compute is isolated. Attestation provides verifiable proof of the execution environment before inference begins. "We have a contract" becomes "here is a cryptographic attestation of exactly what ran, on what hardware, with what software stack."
That's the answer the compliance team is asking for. It's also the answer that closes the enterprise deal.
WHY NVIDIA AND RED HAT TOGETHER CHANGES THE TIMELINE
Confidential computing for CPU workloads has been available in cloud environments for a few years. What's been missing is the GPU — because the models that matter for enterprise AI run on GPUs, and extending TEE isolation to GPU memory and compute is genuinely hard.
NVIDIA solving this for Hopper, HGX, and Blackwell in a single GA release — with multi-GPU passthrough — means the workloads that enterprises actually want to run confidentially can now run confidentially. Not some future generation of hardware. NVIDIA H100 is already deployed in enterprise data centers and cloud environments today.
Red Hat shipping on the same timeline matters for a different reason: it collapses the distance between "this is technically possible" and "my team can actually deploy this." OpenShift is how a substantial portion of enterprise Kubernetes runs. When Red Hat ships something, enterprise infrastructure teams have a supported, vendor-backed path forward. The experimental phase is over.
The signal in both companies shipping together isn't subtle. When NVIDIA and Red Hat align on a capability at the same GA milestone, it's because enterprise demand pulled them there. This isn't supply pushing innovation into an indifferent market. It's infrastructure catching up to a category of demand that's been growing without a good answer.
There's a second-order implication worth sitting with. When you can run multi-GPU confidential workloads on Hopper in your own data center — standard Kubernetes operator, Red Hat OpenShift, no rewrite — you have a reference point that didn't exist before. And reference points change conversations.
That technical capability has a market implication that runs alongside it.
Major cloud providers have partial confidential compute stories. None has delivered multi-GPU passthrough at GA with the scope of what NVIDIA is shipping for on-prem. Right now, your own data center infrastructure can offer stronger isolation guarantees for sensitive AI workloads than your cloud provider can. That's a new dynamic.
What enterprises do with that dynamic is their call. But the question "why can't I get the same cryptographic guarantees in your cloud that I get in my own data center?" is now a fair one to ask. If clustered confidential GPU environments — isolation that extends across multi-node GPU fabrics, not just a single node — become the expectation for sensitive AI workloads at scale, the providers who close that gap first will have something real to offer enterprises that are currently being told to accept less.
WHAT COCO SOLVES — AND WHAT IT DOESN'T
Confidential Containers closes specific, structural data leak vectors. A memory dump no longer exposes live GPU inference — the memory is encrypted and the isolation boundary holds. SDK telemetry can be blocked at the network perimeter before it phones home with enterprise queries. APM tooling sees latency metrics, not prompt content. These aren't theoretical wins. They address bleeds that exist in every AI stack by design, that don't show up in logs, and that most teams have no visibility into.
But the isolation layer alone doesn't tell you who is running the workload, what policies govern what it's allowed to access, or produce the signed evidence chain that your infosec team, compliance function, and regulators are actually asking for. Hardware-backed memory encryption is necessary. It's not sufficient.
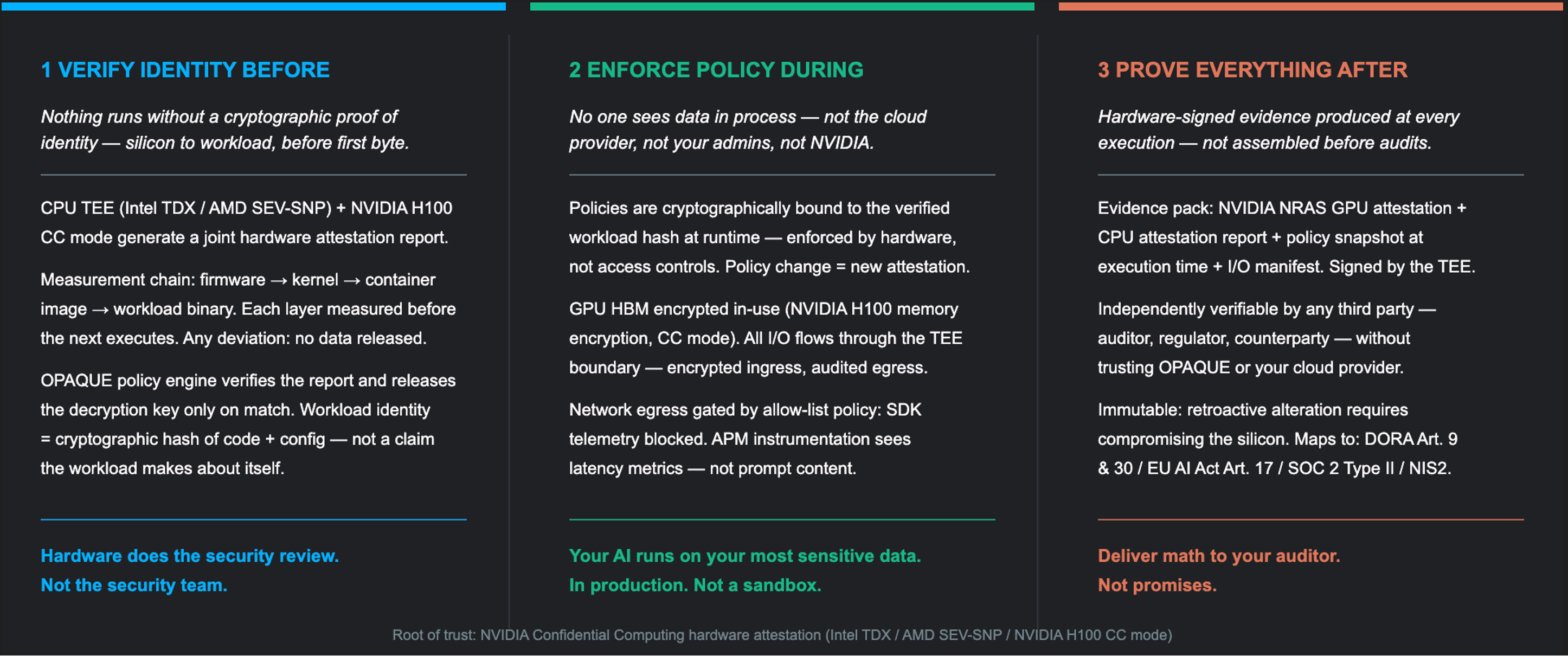
The complete answer to Confidential AI requires three things working together — and all three are grounded in the hardware attestation the TEE generates. That attestation report is the root of trust: a cryptographic statement from the hardware itself certifying exactly what is running inside the execution environment, what software stack it's built on, and that the isolation boundary is intact. Everything else builds from it.
Cryptographic enforcement of identity — workload identity that's derived from the attestation report, not asserted by the workload itself. You know what is actually running inside the TEE because the hardware told you, not because the software claimed it. Policy binding to the runtime — enforcement of what data can enter the execution environment, what can exit, and under what conditions, gated on a verified attestation before inference begins. No attestation, no data. And hardware-signed attestation artifacts — a tamper-proof, independently verifiable evidence chain rooted in that same TEE attestation, that maps to the frameworks regulators are now requiring: DORA Article 9 and 30, the EU AI Act, SOC 2.
Identity. Policy. Proof. All three derive their validity from the hardware attestation that NVIDIA's CoCo stack generates.
That's what makes them cryptographic guarantees rather than administrative ones — the root of trust is silicon, not a contract or a screenshot of a configuration AI systems commonly ignore by their very architecture.
OPAQUE builds the layer that delivers all three. As an NVIDIA Enterprise Embedded Partner licensing NIM with the Confidential Computing license, we work directly on this stack — which is why we can say with confidence that the hardware attestation is real, the isolation boundary holds, and the full solution is available today. And as the AI threat landscape has matured, the attack vectors targeting AI systems have become increasingly well-documented. We mapped the AI-specific threat coverage against the MITRE ATLAS framework in a paper available at opaque.co — if you're trying to understand which attacks a Confidential AI stack actually mitigates, and which ones require additional controls, it's worth reading before you architect your production deployment.
The hardware is ready. The policy layer is available. And everything that makes this credible — identity verification, runtime enforcement, the audit trail your regulators will be asking for — flows from a single hardware attestation report. Silicon vouches for the execution environment. Not a contract. Not a configuration. If compliance, legal, or your CISO is blocking production deployment on your most sensitive AI workloads, the technical objections are answered: hardware attests what's running before data is released; cryptographic policy controls what can enter and leave at runtime; a hardware-signed evidence pack maps to DORA, the EU AI Act, and SOC 2. The question is whether you're building on the stack that provides all three.
THE LONGER VIEW
Last year, enterprise AI teams discovered their observability tooling was capturing full prompt content and shipping it to third-party platforms — 90-day retention, by default, in ToS they'd already signed, without changing a single setting. That scenario is one of 46 exposure vectors we mapped across the full AI stack: compute plane, control plane, application layer, and trust boundary handoffs. None requires an attacker. None show up in your logs.
The pattern is familiar. Encrypted web traffic was "too slow, too complex" until the threat model made the trade off obvious — and then unencrypted became the thing that triggers a browser warning. Structural default exposure always resolves the same way.
GPU confidential computing is that inflection for AI — but the full answer isn't just the hardware layer. NVIDIA and Red Hat ship the foundation: hardware-attested execution that encrypts GPU memory and isolates the compute boundary. Closing the full 46-vector surface requires extending that foundation through cryptographic enforcement of identity, policy, and proof across all four trust boundaries. Confidential AI — hardware-rooted, runtime-enforced, audit-provable — is the only architecture that makes "secure AI" mean something other than a contract.
The enterprises building on top of this now are the ones whose AI roadmaps won't be rewritten by the compliance team eighteen months from now.
FURTHER READING
● OPAQUE — A Dozen Ways Your AI Stack is Bleeding Data: opaque.co
● OPAQUE — MITRE ATLAS Confidential AI Threat Coverage: opaque.co
● NVIDIA GPU Operator — Confidential Containers
● Kata Containers + NVIDIA GPU Passthrough
● CC Summit 2026 — Confidential Computing Summit (hosted by: OPAQUE + Linux Foundation)