Our migration to monorepo: Part 1
Introduction
Our team spent years at UC Berkeley actively building open-source software to support our published research. The open source software, the MC2 Project, is a platform consisting of various libraries and packages that enable secure collaborative analytics and machine learning. While building the platform we created a repository (repo) for each paper; as a result, we were left with a number of distinct and decoupled repos.
At Opaque, we’re building upon the open source software our team had previously developed. During our early efforts in doing so, however, we didn’t consider the effect the separation of repos within the MC2 project might have as our codebase grew; after all, most complex systems benefit from modularity.
However, as we began integrating these individual components into a single platform, the modularized codebase with multiple repositories (the polyrepo) created hurdles and complexities within our engineering workflow. We realized that something needed to change and began considering moving all of our code into a single encapsulating repo, a monorepo, that would almost paradoxically simplify our lives drastically.
In this post, we discuss our journey towards the monorepo, going in-depth about the problems the polyrepo architecture created, the potential downsides of a monorepo and how we thought about them, and our execution of the monorepo migration.
Why we started with a polyrepo
The MC2 project contains three distinct open-source repositories:
opaque-sql: secure Spark SQL (SQL analytics) within hardware enclavessecure-xgboost: secure XGBoost training and inference within hardware enclavesmc2: A client application for single-party interactions with eitheropaque-sqlorsecure-xgboost
At Opaque, we forked the open source repositories into our closed source and added three additional repositories:
tms: An enclave application to manage trust and facilitate multiparty collaborationutils: A library for centralized cryptographic and serialization functionalityfrontend: A frontend application for runningmc2
Throughout the rest of the article we will refer to opaque-sql as just sql, and mc2 as client.
Problems with the polyrepo
While the polyrepo initially seemed like a clean and organized approach, we quickly ran into a number of complications that affected productivity and organization:
A single change required multiple PRs: Making one functional change would oftentimes require multiple PRs. This produced a number of undesirable effects:
- PR reviewers were forced to navigate across multiple repos when reviewing a single feature change
- Engineers would need to know which branches across repos were compatible with each other, and manually checkout those versions in their local workflow
- Before we merged any PR, it must have passed our CI tests (e.g. build, unit, and integration tests). However, when a change affected multiple repos, our automatic CI would fail since the changes in one repo would be incompatible with the
masterbranch of the other repos. As a result, these scenarios required manual testing, and merging the PRs had to be done simultaneously in order to not break anything.
Cumbersome release process: With a polyrepo structure, creating a release meant creating a new branch in each repo and tagging a commit in each repo. With the 6+ repos we had for our product, this meant creating 6+ new branches and 6+ tags for each release.
Duplicate build code: Even though all of our components ran in the same environment, the polyrepo structure forced us to maintain duplicate build scripts in each repo. As a result, any change to the runtime environment required modifying multiple files across repos and managing the resulting set of PRs. To address this, we had originally created a separate ci-cd repo which centralized build logic across all of our different services, but this resulted in yet another repo that had to be maintained.
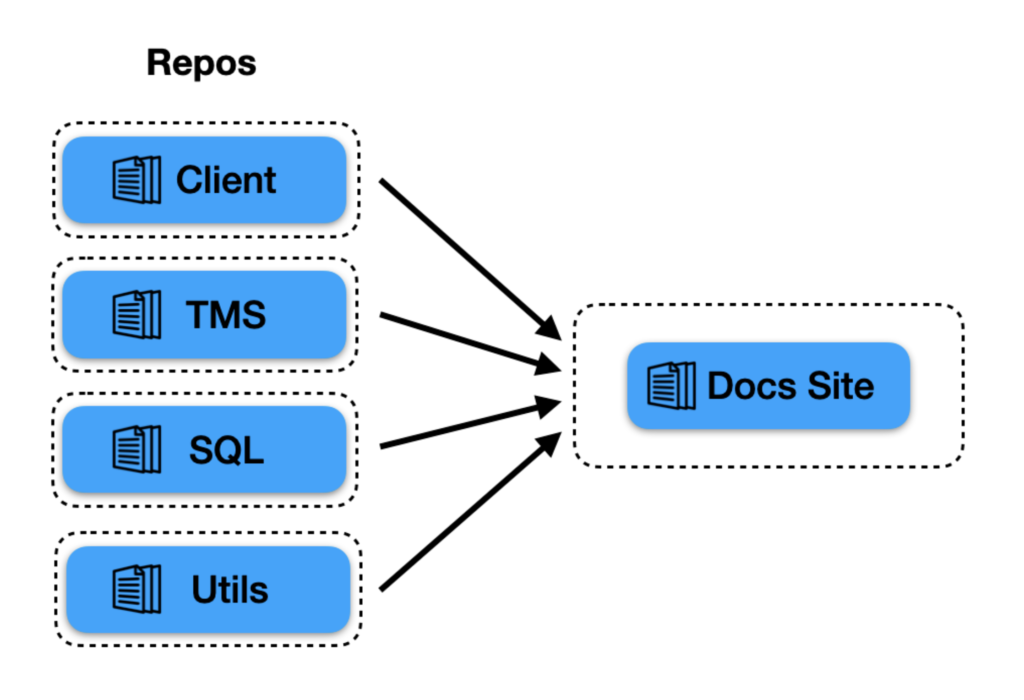
Convoluted documentation build: Initially, each of our repos contained its own documentation, but we wanted to centralize documentation for our entire codebase on a single site. We did not, however, want to move documentation out of its associated repository since that would mean that any change would always require at least two PRs: one PR for the code change and one PR for the documentation change. As a result, our documentation process quickly became complex: the documentation build required pulling from different sources and relied on event dispatches to rebuild the centralized documentation on a push to any relevant repo.
To summarize, as Opaque’s components became increasingly inter-connected, some amount of centralization across repos became necessary to reduce duplicate code and increase engineer productivity. However, these requirements inherently clashed with the polyrepo structure and resulted in complicated and convoluted workflows.
Luckily, we identified these issues relatively early on, and immediately prioritized looking for a solution. A monorepo—where all of our distinct repos would be moved into logically separate directories within a single repo—seemed like a promising direction.
Potential problems (and solutions) with the monorepo
At a high-level, the monorepo seemed like an ideal solution: it allowed for the centralization we needed while maintaining logical separation between distinct components. However, we thought of a number of issues that we would face with a monorepo:
Losing commit history: Initially, we thought that migrating to a monorepo simply meant copying all the code from our other repos into one giant repo. But this would cause us to lose all our commit history (and would prevent us from identifying who to blame for a bug! Just kidding…). However, after more research, we realized that Git allowed us to merge everything together while retaining commit history. We’ll walk through exactly what we did in part 2 of this blog post
Long build times: Keeping all of our code in one repo would mean longer build times and require building/testing all of our components in any PR, right? Nope. To solve this, we could (1) parallelize builds and (2) add some simple logic to only build/test the parts of our codebase that were actually modified in a PR.
Git / IDE Performance: While the size of our aggregate codebase isn’t yet large enough to cause any noticeable performance overhead, we realized that a giant codebase may later mean worsened Git and IDE performance, as many, many more files would need to be parsed. To improve performance down the line, we can do things like Git Shallow Clone or Git sparse-checkout, or use a tool like VFS for Git.
Difficulty in switching: Lastly, actually executing the migration would create some overhead. We’d have to modify existing developer environments to use the monorepo and associated Git remote, move all outstanding PRs to the new monorepo, aggregate all our code into on repo, and modify our CI/CD pipeline and documentation build that had previously been written for a polyrepo.
All in all, we found solutions to the issues we foresaw, and decided that migrating to a monorepo would be the better move in the long run.
Continued in part 2…
In this first part of the blog post, we described the issues with our existing polyrepo structure and the benefits migrating to a monorepo would bring, and shared solutions to problems we foresaw with the monorepo. In part 2, we discuss our process for executing the migration—how we aggregated our code into one repo while maintaining commit history. We also walk through a working example to highlight how much simpler having a monorepo is.
Read part 2.